写在前面的话
为啥会想到写关于PlayWright的东西,其实也是同事和网友的鼓励,都想全面学习一下这个新框架,行吧,那就写吧。虽然我也没接触多久,不过从源代码来看,整体还是比较简单的,再基于十多年的工作经验,以及Selenium和Cypress的使用经历,把自动化的这点东西用PlayWright展现一下,并不是多复杂的事情。
学一个框架,并没有什么困难的,跟着来吧。
PlayWright是啥
PlayWright是由微软开发的一款WebUI自动化测试框架,中文该怎么解释呢?也许可以叫“编剧”,编写了什么?自然是自动化测试的案例咯。
PlayWright旨在提供一种跨平台、跨语言、跨浏览器,并且能支持移动端浏览器的自动化测试框架。

就像它的官方主页描述的那样:
- 它的自动等待,页面元素的智能断言,以及执行追踪特点,使得它能很好的应对了Web页面的不稳定性。
- 在不同于浏览器的进程中控制浏览器执行测试,这使得PlayWright摆脱了典型的进程内测试运行器的限制。并且可以穿透
Shadow DOM。 - Playwright为每个测试创建一个浏览器上下文,浏览器上下文相当于一个全新的浏览器配置文件,这提供了零开销的完全测试隔离,创建一个新的浏览器上下文只需要几毫秒。
- 提供了代码生成器,单步调试,追踪查看功能。
PlayWright VS Selenium VS Cypress
现在有什么好用的WebUI自动化测试框架?脱颖而出的自然是发展了十多年的Selenium,以及这几年比较火的Cypress。和我们这里将要介绍的PlayWright相比,有什么差别呢?我特意整理了一张表,给大家参考下:
| 特性 | PlayWright | Selenium | Cypress |
|---|---|---|---|
| 支持的语言 | JavaScript, Java, C#, Python |
JavaScript, Java, C#, Python, Ruby |
JavaScript/TypeScript |
| 支持的浏览器 | Chrome, Edge, Firefox, Safari |
Chrome, Edge, Firefox, Safari, IE |
Chrome, Edge, Firefox, Safari |
| 测试框架 | 所支持语言的测试框架 | 所支持语言的测试框架 | 所支持语言的测试框架 |
| 易用性 | 使用和配置都简易 | 设置较为复杂, 有一定学习成本 |
使用和配置都简易 |
| 代码难度 | 简易 | 中等 | 简易 |
| DOM操作 | 简易 | 中等 | 简易 |
| 社区成熟的 | 逐步完善 | 极为成熟 | 较为成熟 |
| 是否支持无头模式 | 是 | 是 | 是 |
| 是否支持并发 | 支持 | 支持 | 依赖CI/CD工具 |
| iframe支持 | 支持 | 支持 | 通过插件支持 |
| Driver | 不需要 | 每一种浏览器匹配一种Driver | 不需要 |
| 多Tab操作 | 支持 | 不支持 | 支持 |
| 拖拽 | 支持 | 支持 | 支持 |
| 内置报告 | 有 | 无 | 有 |
| 跨域 | 支持 | 支持 | 支持 |
| 内置调试功能 | 有 | 无 | 有 |
| 自动等待 | 有 | 无 | 有 |
| 内置截屏/录屏 | 有 | 无录屏 | 有 |
整体对比来看差别不大,对与测试工程师来说,能熟练使用
JavaScript/TypeScript的不多,所以能支持Java、C#、Python语言的测试框架显然会更受测试工程师的欢迎。
从原理方面而言,PlayWright和Selenium很接近,控制Chronium类型的浏览器,都是使用了Google的Remote Debugging Protocol,对Firefox这类没有Remote Debugging Protocol的,则是采用了挂接js的方式,差别是Selenium封装了一个Driver,PlayWright则是直接调用。而Cypress则是直接使用了js来控制浏览器。
从支持的浏览器看,Selenium比其他两款多支持了IE浏览器,不过随着IE逐渐退出历史舞台,这一点已经不重要了。
易用性而言,三者其实差不多,都有一定的门槛,但是PlayWright和Cypress如果只是按照官方Demo写的简单用一下,那确实够方便,比Selenium更友好。但是要深入使用的话,三者都是有一定难度的。
执行效率而言,Cypress最高效,其次是PlayWright,最慢的是Selenium。经过实验,PlayWright的执行效率大概比Selenium(最新版本)高40%左右。
社区资源而已,Selenium是最成熟的,你在使用Selenium的时候,不管遇到什么问题,都能在网络上找到答案。Cypress这两年的资源也越来越多,而PlayWright还比较新,所以网上能找到的资料还比较少,很多问题需要自己读源码来理解。
至于录制,生成代码的功能,其实我不太关注,对真正做自动化测试来说也不实用,因为自动化一旦成规模,需要的是工程化的管理,录制生成的代码都要进行工程化改造,与其要改一堆代码来适配自己公司的工程化框架,还不如从一开始就自己手写更方便。
开始使用
虽然PlayWright支持多语言,实际上核心还是要依赖node.js,不管是Python版本还是Java版本,在初始化时候都需要检查node.js环境,并在初始化的时候,下载一个node.js的driver,而Java也好Python也好,封装的API都是需要调用这个程序。所以为了回归本源,这里主要使用JavaScript/TypeScript来介绍。
安装与Demo
首先需要确定本机上已经安装了最新版本的node.js,这个环境的安装就不再这里说了,自行去看node.js官网的说明。
接着就可以使用了,PlayWright的环境准备很简单,几乎不用配置什么东西,除非你需要使用自己的测试框架来创建PlayWright测试。
我们现在用PlayWright自身框架来创建测试项目,npm或者yarn都可以:
# 使用npm
npm init playwright@latest
# 使用yarn
yarn create playwright
注意,要在你准备好的项目目录下执行。
接着就是会引导你进行输入:
- 使用TypeScript还是JavaScript,默认是TypeScript;
- 测试案例目录名称;
- 是否需要添加一个GitHub的Action,用于在GitHub仓库中执行CI,默认是False;
- 是否需要安装PlayWright支持的浏览器,默认是True。
选择完成后,如果你在最后一步选择了需要它自行下载浏览器,那么PlayWright会进行必要的下载,它将从默认的网址去下载各个浏览器(chromium、firefox、webkit),这个过程时间会有点长,请耐心等待完成。
这个下载过程只会在机器上首次创建PlayWright测试项目的时候会经历,下载过一次后,只要PlayWright版本没有升级,那么就不会再次下载。原因这里就不说了,后面的章节我会详细介绍原因的。
PlayWright会自动生成项目模版,结构如下:
playwright.config.ts # PlayWright配置文件
package.json # nodejs配置文件
package-lock.json # nodejs配置锁定
tests/ # 你指定的测试案例目录
example.spec.ts # 测试案例的一个模版,实际编写时候可以删掉
tests-examples/ # 样例目录
demo-todo-app.spec.ts # 测试案例的样例
如果你想自己来组织目录,使用自己的测试框架,那就把PlayWright作为一个依赖引入,我会在后面的章节介绍这种做法。
因为有个example.spec.ts ,所以现在是可以直接运行的,在命令行执行:
npx playwright test
整个执行过程你将不会看到有任何浏览器弹出来,自动执行这个测试,而是在默默的运行,看下执行结果:
Running 6 tests using 6 workers
6 passed (21.8s)
To open last HTML report run:
npx playwright show-report
显示执行了6个测试案例,并且使用了6个“工人”(workers),总共耗时21.8秒,如果想看html版本的测试报告,请运行如下命令。
npx playwright show-report
执行这个命令后会自动启动一个本地web服务,并且自动打开一个浏览器,展示HTML格式的报告如下:
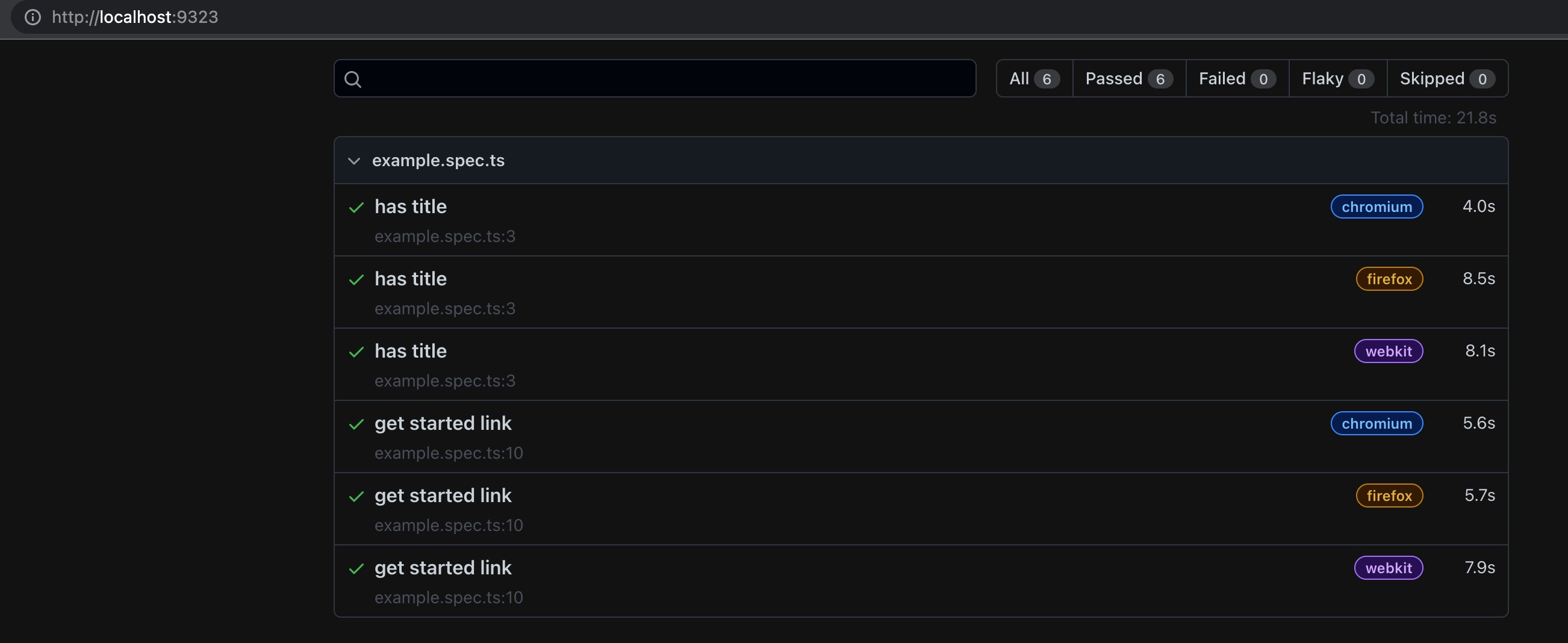
从这个报告中我们可以看到其实执行了两个测试案例,一个叫”has title”,另一个叫”get started link”,这两个测试案例分别在三种浏览器上运行的结果,测试案例名称前面的勾子✅,则代表测试通过,如果失败会用红叉表示。
example源码解读
我们来看看刚才执行的那个example.spec.ts测试案例源码文件:
import { test, expect } from '@playwright/test';
test('has title', async ({ page }) => {
await page.goto('https://playwright.dev/');
// Expect a title "to contain" a substring.
await expect(page).toHaveTitle(/Playwright/);
});
test('get started link', async ({ page }) => {
await page.goto('https://playwright.dev/');
// Click the get started link.
await page.getByRole('link', { name: 'Get started' }).click();
// Expects the URL to contain intro.
await expect(page).toHaveURL(/.*intro/);
});
这里我们看到了两个test方法,test有两个参数,第一个参数是测试案例的名称,我们看到了”has title”和”get started link”,这就是我们之前在报告中看到的两个测试案例的名称。第二个参数是一个函数,这里用一个lambda表达式来表示:
async (参数) => {
函数身体部分
}
async关键字表示这个函数是一个异步函数。函数的参数,在代码中写的是{ page },这表示一个对象,这个对象中有一个元素是page,类型是@playwright/test包中的Page。这个函数的原型,是这样的:
function testFunction(args: PlaywrightTestArgs & PlaywrightTestOptions & PlaywrightWorkerArgs & PlaywrightWorkerOptions, testInfo: TestInfo) void | Promise<...>
看起来很复杂吗?其实看清楚就明白了,这个函数有两个参数,一个叫args类型是PlaywrightTestArgs & PlaywrightTestOptions & PlaywrightWorkerArgs & PlaywrightWorkerOptions,第二个参数叫testInfo,类型是TestInfo,返回类型是void或Promise。
而page是PlaywrightTestArgs类中的一个成员。
在函数体中,page.goto方法很明显是页面跳转到一个指定的网页地址,前面的await必须要加,因为page.goto方法是一个异步方法,如果不加await那么在页面还没发生跳转就会执行后面的语句了。
expect(page).toHaveTitle(/Playwright/)很明显是一句断言语句,可以解读为“期望xx对象有什么”,那么这里明显是期望当前的页面有”Playwright”这个title,注意这里/Playwright/这种正斜杠的写法,是JavaScript中正则表达式的语法,只要匹配有Playwright字符串就判定为true了。前面的await是和前一句同样的意思,等待异步完成。
第二个测试案例,和第一个基本类似,仅仅多了一句
await page.getByRole('link', { name: 'Get started' }).click();
这一句是操作页面的一个元素进行点击操作。page.getByRole方法是一个页面元素的定位方法,返回一个页面元素,然后执行点击。
再整体看一遍example.spec.ts文件,是不是感觉很简单而且可读性很高呢?这就是PlayWright的魅力了。
命令行说明
在node项目中,我们一般使用npx来执行可执行包。在我们这个项目中,有一个node_modules目录,里面存放了项目所有下载的依赖包。其中有一个.bin目录,里面就是一些可执行的二进制包。这里是playwright可执行文件。而npx其实就是去执行这个文件。
我们在前面用过一个命令来执行测试:
npx playwright test
其实也可以直接去执行.bin目录下的playwright可执行文件:
./node_modules/.bin/playwright test
现在看看有哪些常用的执行测试的方法:
执行所有测试
npx playwright test执行指定的测试案例文件
npx playwright test landing-page.spec.ts执行一组测试案例(
tests/todo-page/和tests/landing-page/两个目录下的所有案例)npx playwright test tests/todo-page/ tests/landing-page/执行测试案例文件名包含landing或者login的案例文件
npx playwright test landing login执行测试案例的名称为”add a todo item”的
npx playwright test -g "add a todo item"-g参数其实是一个过滤参数在“有头”模式下执行测试(就是会看到浏览器被打开,而默认的无头模式则不会看到有浏览器打开)
npx playwright test landing-page.spec.ts --headed指定浏览器执行测试
npx playwright test landing-page.ts --project=chromium调试测试案例:
npx playwright test --debug这时候playwright会打开一个浏览器,开始单步执行测试案例。
调试指定的测试案例脚本文件:
npx playwright test example.spec.ts --debug调试测试脚本文件指定行号的测试案例:
npx playwright test example.spec.ts:10 --debug如图:

显示测试报告
npx playwright show-report
录制功能
在命令行输入codegen就可以启动playwright的录制功能:
npx playwright codegen https://blog.testops.vip/
录制下的代码,可以复制黏贴到你的文件中。不过录制功能感觉略为简易,鼠标的一些特殊操作没法记录,比如悬停之类的,基本操作是没问题的。所以录制功能仅作为一个参考吧,不用太依赖。
追踪查看
playwright默认情况下就开启了追踪机制,并定义在执行测试案例失败后的第一次重试时会记录追踪日志。
可以在配置文件playwright.config.ts中看到相关的配置信息:
const config: PlaywrightTestConfig = {
// 不相关的省略
retries: process.env.CI ? 2 : 0, // 如果在CI环境,则有2次重试
use: {
trace: 'on-first-retry', // 在第一次重试时记录追踪日志
},
}
在执行测试时,也可以通过命令行直接开启:
npx playwright test --trace on
开启trace后,执行完测试会生成一个trace.zip压缩包,可以在报告中查看:
trace报告也可以用命令行直接打开:
npx playwright show-trace trace.zip
如果不加trace.zip文件名,那会在弹出的页面中提示你指定trace文件或者直接将trace文件拖进当前的页面上。
打开trace文件可以看到如下信息:
详解PlayWright
配置文件说明
我们仔细拆解一下PlayWright的启动机制,当我们启动测试时,playwright会首先加载playwright.config.ts文件中定义的PlaywrightTestConfig对象,这个对象的设置分为全局参数设置和项目(project)参数设置,注意项目参数设置会覆盖全局设置。具体的内容我们后面会逐步提到。
而在执行case之前,我们定义的测试案例函数(还记得我们前面提过的,test方法所需要的两个参数的第二个,是一个函数式的参数吗?),它所传入的PlaywrightTestArgs & PlaywrightTestOptions & PlaywrightWorkerArgs & PlaywrightWorkerOptions这四个对象,其实都来自于配置文件中的全局参数以及项目参数的use属性的设置。
说到这里,可能没有什么直观的感觉,也不明白到底有什么用。没关系,我们先来看看playwright.config.ts文件中如何配置跟浏览器相关的属性。
在playwright.config.ts文件中,配置use对象,就有关于浏览器相关的属性:
const config: PlaywrightTestConfig = {
// 其他内容略过
use: {
/*
browserName用于设置浏览器名称,这个名称一般在全局参数中不用配置,通常在`项目`(project)参数中设置,只可以有三个可选值:"chromium" 、"firefox"、"webkit",默认值为'chromium'。
*/
browserName: 'chromium',
/*
defaultBrowserType用于设置默认浏览器,同上面的browserName类似,只是这个属性用于设置默认值。
*/
defaultBrowserType: 'chromium',
/*
headless用于设置是否采用无头模式运行浏览器,默认值是true
*/
headless: true,
/*
channel用于指定使用本机按照的浏览器,目前可以支持的值是"chrome","chrome-beta", "chrome-dev", "chrome-canary","msedge", "msedge-beta", "msedge-dev", "msedge-canary",需要注意的是,本机浏览器需要默认安装在本机上。如果不设置,则表示使用playwright自己下载的浏览器。
*/
channel: 'chrome',
/*
启动浏览器的相关配置
*/
launchOptions: {
/*
传给浏览器的参数,必须是浏览器所支持的命令行参数,比如chromium浏览器,可以参考http://peter.sh/experiments/chromium-command-line-switches
*/
args: [
"--force-first-run",
],
/*
和前面的channel是同一含义。
*/
channel: 'chrome',
/*
是否在沙盒内运行,默认是false
*/
chromiumSandbox: true,
/*
是否打开开发者工具,只对chromium浏览器有效,当设置为true时,之前设置的headless则无效。默认值为false
*/
devtools: true,
/*
用于设置浏览器下载文件的目录
*/
downloadsPath: '/temp/download/',
/*
指定浏览器的路径,一般不在全局配置中指定,而在项目配置中配置,一旦配置了浏览器的可执行文件的位置,那么就不会去找playwright自己默认下载的浏览器的位置了。
*/
executablePath: '/app/Google Chrome/chrome',
/*
使用SIGHUP“挂起”(Hang Up)信号关闭浏览器,默认是true
*/
handleSIGHUP: true,
/*
使用Ctrl+C信号关闭浏览器,默认是true
*/
handleSIGINT: true,
/*
使用SIGTERM信号关闭浏览器,默认是true
*/
handleSIGTERM: true,
/*
和前面的headless是同一含义。
*/
headless: true,
/*
是否忽略playwright本身启动浏览器时后传递给浏览器的参数,默认是false
*/
ignoreDefaultArgs: true,
/*
用于设置代理服务器
*/
proxy: {
/*
HTTP和SOCKS代理都支持
*/
server: 'http://myproxy.com:3128',
/*
指定哪些需要绕开代理,用逗号分开
*/
bypass: ".com, chromium.org, .domain.com",
/*
代理用户名
*/
username: "myname",
/*
代理密码
*/
password: "123456",
},
/*
设置操作间隔的等待时间,用于减慢playwright执行的速度,单位是毫秒
*/
slowMo: 200,
/*
等待浏览器启动的超时时间,单位为毫秒,默认值为30000毫秒(30秒)
*/
timeout: 30000,
/*
用于设置追逐记录trace包的存放位置
*/
tracesDir: 'traces',
},
/*
是否接受文件下载,默认值为true
*/
acceptDownloads: true,
/*
设置知否绕开页面的内容安全策略(Content-Security-Policy)
*/
bypassCSP: true,
/*
用于设置页面匹配的css的media属性,比如某些页面的css设置了media属性,来展示dark模式,那就可以不用手工去选择,而直接匹配上,可选的值为:'light'`, `'dark'`, `'no-preference'。默认值是'light'
*/
colorScheme: 'dark',
/*
是否运行js脚本运行,默认值为true
*/
javaScriptEnabled: true,
/*
设置浏览器本地语言
*/
locale: 'zh-CN',
/*
设置浏览器获取的权限,权限可以参考https://playwright.dev/docs/api/class-browsercontext#browser-context-grant-permissions
*/
permissions: ['geolocation', 'camera'],
/*
同前面的launchOptions中的proxy属性
*/
proxy: {/*略*/},
/*
浏览器窗口的大小,默认值为1028*720
*/
viewport: {
width: 1028,
height: 720,
},
/*
基础url地址。配置后,当使用page.goto("/foo")的时候,其实就会和baseUrl拼接成完整的地址。
*/
baseURL: "https://www.baidu.com",
/*
浏览器上下文,在playwright工具的概念中,一个page,是运行在一个context上下文中的,所以这个context配置的值,会对所有在其中的page有影响。
*/
contextOptions: {
/* 大部分属性和前面一样,此处略 */
},
},
projects: [
{
/* 其他属性略 */
use: {
/* 此处为配置单个项目的属性,和前面的全局的use属性其实是一样的,只不过这里配置的在当前这个项目中会覆盖全局属性 */
}
},
/* 其他类似的,略 */
]
}
虽然我在这里只列了和浏览器相关的设置属性,不过大家也都基本能看明白了,整个playwright的配置文件,其实分成了全局配置和项目配置,包含的属性是一样的,只不过项目配置会覆盖全局配置。
启动浏览器
根据我们在配置文件中的配置,playwright会将对应的浏览器启动起来。
在例子中,配置文件里面的projects属性配置了3个项目:
projects: [
{
name: 'chromium',
use: {
...devices['Desktop Chrome'],
},
},
{
name: 'firefox',
use: {
...devices['Desktop Firefox'],
},
},
{
name: 'webkit',
use: {
...devices['Desktop Safari'],
},
},
]
所以我们会执行3个项目的测试,这三个项目名称分别叫”chromium”,”firefox”,”webkit”,每个项目都会独立去运行example中的两个测试案例,所以为何我们看到测试结果一共执行了6个测试,原因就在此处。
而...devices['Desktop Chrome']表示引用了devices对象的’Desktop Chrome’的值,这是内置的一个常量,配置了浏览器默认值,除了’Desktop Chrome’,还有很多常量,我们来看下:
type Devices = {
"Blackberry PlayBook": DeviceDescriptor;
"Blackberry PlayBook landscape": DeviceDescriptor;
"BlackBerry Z30": DeviceDescriptor;
"BlackBerry Z30 landscape": DeviceDescriptor;
"Galaxy Note 3": DeviceDescriptor;
"Galaxy Note 3 landscape": DeviceDescriptor;
"Galaxy Note II": DeviceDescriptor;
"Galaxy Note II landscape": DeviceDescriptor;
"Galaxy S III": DeviceDescriptor;
"Galaxy S III landscape": DeviceDescriptor;
"Galaxy S5": DeviceDescriptor;
"Galaxy S5 landscape": DeviceDescriptor;
"Galaxy S8": DeviceDescriptor;
"Galaxy S8 landscape": DeviceDescriptor;
"Galaxy S9+": DeviceDescriptor;
"Galaxy S9+ landscape": DeviceDescriptor;
"Galaxy Tab S4": DeviceDescriptor;
"Galaxy Tab S4 landscape": DeviceDescriptor;
"iPad (gen 6)": DeviceDescriptor;
"iPad (gen 6) landscape": DeviceDescriptor;
"iPad (gen 7)": DeviceDescriptor;
"iPad (gen 7) landscape": DeviceDescriptor;
"iPad Mini": DeviceDescriptor;
"iPad Mini landscape": DeviceDescriptor;
"iPad Pro 11": DeviceDescriptor;
"iPad Pro 11 landscape": DeviceDescriptor;
"iPhone 6": DeviceDescriptor;
"iPhone 6 landscape": DeviceDescriptor;
"iPhone 6 Plus": DeviceDescriptor;
"iPhone 6 Plus landscape": DeviceDescriptor;
"iPhone 7": DeviceDescriptor;
"iPhone 7 landscape": DeviceDescriptor;
"iPhone 7 Plus": DeviceDescriptor;
"iPhone 7 Plus landscape": DeviceDescriptor;
"iPhone 8": DeviceDescriptor;
"iPhone 8 landscape": DeviceDescriptor;
"iPhone 8 Plus": DeviceDescriptor;
"iPhone 8 Plus landscape": DeviceDescriptor;
"iPhone SE": DeviceDescriptor;
"iPhone SE landscape": DeviceDescriptor;
"iPhone X": DeviceDescriptor;
"iPhone X landscape": DeviceDescriptor;
"iPhone XR": DeviceDescriptor;
"iPhone XR landscape": DeviceDescriptor;
"iPhone 11": DeviceDescriptor;
"iPhone 11 landscape": DeviceDescriptor;
"iPhone 11 Pro": DeviceDescriptor;
"iPhone 11 Pro landscape": DeviceDescriptor;
"iPhone 11 Pro Max": DeviceDescriptor;
"iPhone 11 Pro Max landscape": DeviceDescriptor;
"iPhone 12": DeviceDescriptor;
"iPhone 12 landscape": DeviceDescriptor;
"iPhone 12 Pro": DeviceDescriptor;
"iPhone 12 Pro landscape": DeviceDescriptor;
"iPhone 12 Pro Max": DeviceDescriptor;
"iPhone 12 Pro Max landscape": DeviceDescriptor;
"iPhone 12 Mini": DeviceDescriptor;
"iPhone 12 Mini landscape": DeviceDescriptor;
"iPhone 13": DeviceDescriptor;
"iPhone 13 landscape": DeviceDescriptor;
"iPhone 13 Pro": DeviceDescriptor;
"iPhone 13 Pro landscape": DeviceDescriptor;
"iPhone 13 Pro Max": DeviceDescriptor;
"iPhone 13 Pro Max landscape": DeviceDescriptor;
"iPhone 13 Mini": DeviceDescriptor;
"iPhone 13 Mini landscape": DeviceDescriptor;
"Kindle Fire HDX": DeviceDescriptor;
"Kindle Fire HDX landscape": DeviceDescriptor;
"LG Optimus L70": DeviceDescriptor;
"LG Optimus L70 landscape": DeviceDescriptor;
"Microsoft Lumia 550": DeviceDescriptor;
"Microsoft Lumia 550 landscape": DeviceDescriptor;
"Microsoft Lumia 950": DeviceDescriptor;
"Microsoft Lumia 950 landscape": DeviceDescriptor;
"Nexus 10": DeviceDescriptor;
"Nexus 10 landscape": DeviceDescriptor;
"Nexus 4": DeviceDescriptor;
"Nexus 4 landscape": DeviceDescriptor;
"Nexus 5": DeviceDescriptor;
"Nexus 5 landscape": DeviceDescriptor;
"Nexus 5X": DeviceDescriptor;
"Nexus 5X landscape": DeviceDescriptor;
"Nexus 6": DeviceDescriptor;
"Nexus 6 landscape": DeviceDescriptor;
"Nexus 6P": DeviceDescriptor;
"Nexus 6P landscape": DeviceDescriptor;
"Nexus 7": DeviceDescriptor;
"Nexus 7 landscape": DeviceDescriptor;
"Nokia Lumia 520": DeviceDescriptor;
"Nokia Lumia 520 landscape": DeviceDescriptor;
"Nokia N9": DeviceDescriptor;
"Nokia N9 landscape": DeviceDescriptor;
"Pixel 2": DeviceDescriptor;
"Pixel 2 landscape": DeviceDescriptor;
"Pixel 2 XL": DeviceDescriptor;
"Pixel 2 XL landscape": DeviceDescriptor;
"Pixel 3": DeviceDescriptor;
"Pixel 3 landscape": DeviceDescriptor;
"Pixel 4": DeviceDescriptor;
"Pixel 4 landscape": DeviceDescriptor;
"Pixel 4a (5G)": DeviceDescriptor;
"Pixel 4a (5G) landscape": DeviceDescriptor;
"Pixel 5": DeviceDescriptor;
"Pixel 5 landscape": DeviceDescriptor;
"Moto G4": DeviceDescriptor;
"Moto G4 landscape": DeviceDescriptor;
"Desktop Chrome HiDPI": DeviceDescriptor;
"Desktop Edge HiDPI": DeviceDescriptor;
"Desktop Firefox HiDPI": DeviceDescriptor;
"Desktop Safari": DeviceDescriptor;
"Desktop Chrome": DeviceDescriptor;
"Desktop Edge": DeviceDescriptor;
"Desktop Firefox": DeviceDescriptor;
}
这些不用多做解释吧,有浏览器,还有手机设备。
devices['Desktop Chrome']前面的三个点号...表示将devices['Desktop Chrome']对象“展平”,将其中的属性取出来作为use对象的属性。那么具体有哪些值呢?我这里举一个devices['Desktop Chrome']的例子:
devices['Desktop Chrome'] = {
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.5481.38 Safari/537.36',
viewport: { width: 1280, height: 720 },
screen: { width: 1920, height: 1080 },
deviceScaleFactor: 1,
isMobile: false,
hasTouch: false,
defaultBrowserType: 'chromium'
}
其实主要就是包含了userAgent,viewport,screen,deviceScaleFactor,isMobile,hasTouch,defaultBrowserType这七个属性。
这里有点奇怪,不能进行浏览器的最大化设置,只能通过设置viewport属性来设置打开的浏览器窗口大小。
chrome浏览器有个小技巧可以实现窗口最大化,那就是使用命令行参数传递给浏览器,做法是在
launchOptions中设置args参数,值为['--start-maximized'],但是请注意,如果在macOS系统中,chromium无法正常最大化,并且viewport的设置也是失效的,可能是个bug。浏览器是否最大化并不会影响测试,除了极为个别的一些情况,所以请不用太在意这些问题。
PlayWright默认会启动自己下载的浏览器,默认情况下,PlayWright下载的浏览器放在如下的目录(和操作系统有关):
- %USERPROFILE%\AppData\Local\ms-playwright —— Windows
- ~/Library/Caches/ms-playwright —— MacOS
- ~/.cache/ms-playwright —— Linux
当然,如果你在安装PlayWright内置的浏览器时没有安装在默认路径,也可以通过设置环境变量来制定到哪个目录去找浏览器,环境变量名字叫PLAYWRIGHT_BROWSERS_PATH,注意,这个路径指到相当于前面所说的ms-playwright这一层就可以。也就是说,ms-playwright里面的目录结构,还是必须和原来的一样,也就是必须像这样的:
chromium-XXXXXX
firefox-XXXX
webkit-XXXX
ffmpeg-XXXX
指定其他的浏览器
表面看,PlayWright只支持Chrome、Firefox、Edge、Safari浏览器,但实际上,从他的下载的浏览器目录来看,因为他支持Chromium,所以实际上只要是使用了Chromium内核的浏览器,PlayWright都可以支持。
在这里,我举一个例子。比如我想使用本地的Bravo浏览器作为测试用的浏览器,那我可以通过executablePath属性来指定浏览器:
launchOptions: {
executablePath: '/Applications/Brave Browser.app/Contents/MacOS/Brave Browser',
},
此时执行测试,就会启动我们安装在本地这个位置的Bravo浏览器,由于Bravo浏览器也是Chromium内核,所以其他操作无区别。那么由此可以举一反三,像国内的360浏览器一样可以操作。
据实验,360浏览器某些版本不支持“无头模式”(headless),必须将headless参数设置成false才能正常启动。
元素定位
在PlayWright中的元素定位基本跟Selenium是类似的,熟悉CSS选择器定位以及xpath定位的同学可以无缝过渡。当然,PlayWright也有自己定义元素的特色,我们在这里仔细讲讲。
PlayWright内置很多很方便的定位器,我们一个一个来研究。
角色定位器(Role)
这是一个官方最为推荐的定位器,从用户角度讲更直观,易于理解,并且稳定。方法为getByRole。
假设现在有一个按钮:
<button>Sign in</button>
我们可以这样来操作点击:
await page.getByRole('button', { name: 'Sign in' }).click();
getByRole方法有两个参数:
role,字符串类型,表示目标角色是什么。
可选值为”alert”|”alertdialog”|”application”|”article”|”banner”|”blockquote”|”button”|”caption”|”cell”|”checkbox”|”code”|”columnheader”|”combobox”|”complementary”|”contentinfo”|”definition”|”deletion”|”dialog”|”directory”|”document”|”emphasis”|”feed”|”figure”|”form”|”generic”|”grid”|”gridcell”|”group”|”heading”|”img”|”insertion”|”link”|”list”|”listbox”|”listitem”|”log”|”main”|”marquee”|”math”|”meter”|”menu”|”menubar”|”menuitem”|”menuitemcheckbox”|”menuitemradio”|”navigation”|”none”|”note”|”option”|”paragraph”|”presentation”|”progressbar”|”radio”|”radiogroup”|”region”|”row”|”rowgroup”|”rowheader”|”scrollbar”|”search”|”searchbox”|”separator”|”slider”|”spinbutton”|”status”|”strong”|”subscript”|”superscript”|”switch”|”tab”|”table”|”tablist”|”tabpanel”|”term”|”textbox”|”time”|”timer”|”toolbar”|”tooltip”|”tree”|”treegrid”|”treeitemoptions,可选参数,是一个对象,用于确定目标元素的一些属性,可用的属性有以下这些:checked,可选参数,布尔型,对应于aria-checked的值或者原生的<input type=checkbox>的值disabled,可选参数,布尔型,对应于aria-disabled或者disabled的值。exact,可选参数,布尔型,如果设置为true,则会精确匹配name属性,大小写敏感,但是忽略左右两边的空格。如果name属性配置了正则表达式,则exact属性被忽略。expanded,可选参数,布尔型,对应aria-expanded设置的值,表示是否被展开。includeHidden,可选参数,布尔型,是否包含隐藏元素,只有被ARIA设置的元素才可以被选中。level,可选参数,数字型,只作用于heading,listitem,row,treeitem这些角色,比如h1~`h6`。name,可选参数,字符串或正则表达式类型,用于匹配accessible name,通常是元素的可见文本。默认情况下忽略大小写,只要有子字符串匹配就认为符合。pressed,可选参数,布尔型,对应aria-pressed的值,表示是否按下。selected,可选参数,布尔型,对应aria-selected的值,表示是否被选中。
官方给出了一些例子:
<h3>Sign up</h3>
<label>
<input type="checkbox" /> Subscribe
</label>
<br/>
<button>Submit</button>
用角色定位器可以这样操作:
await expect(page.getByRole('heading', { name: 'Sign up' })).toBeVisible();
await page.getByRole('checkbox', { name: 'Subscribe' }).check();
await page.getByRole('button', { name: /submit/i }).click();
Label定位器
这个就是普通的label标签定义的文字,通常用在form表单的那些字段的定位,比较方便。看下面的例子:
<label>Password <input type="password" /></label>
操作可以这样写:
await page.getByLabel('Password').fill('secret');
placeholder定位器
顾名思义,就是对应元素的placeholder属性,看例子:
<input type="email" placeholder="name@example.com" />
操作是这样:
await page
.getByPlaceholder("name@example.com")
.fill("playwright@microsoft.com");
文本定位器(Text)
还是看例子:
<span>Welcome, John</span>
匹配文字:
await expect(page.getByText('Welcome, John')).toBeVisible();
精确匹配:
await expect(page.getByText('Welcome, John', { exact: true })).toBeVisible();
正则匹配:
await expect(page.getByText(/welcome, [A-Za-z]+$/i)).toBeVisible();
文本定位器建议用在像
p、div、span这类非交互式的元素定位上,如果是input这类交互式的元素,还是用角色定位器。
替换文本定位器(alt text)
顾名思义,针对有alt属性的元素,一般像img元素,看例子:
<img alt="playwright logo" src="/img/playwright-logo.svg" width="100" />
使用方法:
await page.getByAltText('playwright logo').click();
title定位器
针对有title属性的元素,看例子:
<span title='Issues count'>25 issues</span>
使用方法:
await expect(page.getByTitle('Issues count')).toHaveText('25 issues');
test-id定位器
这是一个比较特殊的定位器,是专门针对测试的,针对一些元素,可以和开发约定一个叫data-testid的属性,用于该元素的定位。看例子:
<button data-testid="directions">Itinéraire</button>
使用方法:
await page.getByTestId('directions').click();
当然,也可以不使用data-testid这个属性,可以自定义名称,需要在配置文件中这样配置:
// playwright.config.ts
import { defineConfig } from '@playwright/test';
export default defineConfig({
use: {
testIdAttribute: 'data-pw'
}
});
那么这样定义后,就约定了testid的属性为data-pw了。再看例子:
<button data-pw="directions">Itinéraire</button>
用法和原来一样。
css/xpath定位
这应该是大家最熟悉的定位方式了,只要是用过selenium的,对这两种定位方式必然倍感亲切。但是根据PlayWright的说法,不管是CSS还是XPATH,都不是推荐的定位方式,因为他们都伴随着很多的不稳定因素,比如少了一层div啦,调整了顺序啦,都会导致定位不到,而使用角色定位器则不会有这方面的问题。当然这是官方的说辞,如果的你能把css/xpath定位写的足够稳定,其实也能起到和角色定位器一样的稳定效果。
先看下用法:
await page.locator('css=button').click();
await page.locator('xpath=//button').click();
await page.locator('button').click();
await page.locator('//button').click();
注意,这里用了通用locator方法,里面的css和xpath可以加上关键字也可以省略。xpath必须以
//或者/开头。
css/xpath定位千万不要写的太长,越长,依赖的中间元素越多,越容易带来定位的不稳定,维护代价也更大。比如下面这些就是很差的写法:
await page.locator(
'#tsf > div:nth-child(2) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input'
).click();
await page
.locator('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
.click();
关于影子DOM中元素的定位
首先理解什么是影子DOM,Shadow DOM(影子DOM)是Web组件的一项技术,它允许你将一个元素的样式和行为封装起来,以便在不同的上下文中(比如外部文档)中使用时,不会和其它元素的样式和行为发生冲突。Shadow DOM的本质是一种类似于虚拟DOM的技术,它将页面中不同的DOM元素封装成一个独立的组件,使得应用更加灵活、可维护性更高。Shadow DOM使用的关键是其隔离性,它为DOM元素提供了一个完全独立的上下文,使得每个DOM元素都能够拥有自己的私有DOM树和样式规则。这样,就能够更加灵活地设计Web应用,同时也能保持应用的高可维护性。
PlayWright默认所有定位器都可以正常操作在影子DOM中的元素,也就是所谓的穿透影子DOM,但是需要注意,使用XPATH表达式是不可以穿透影子DOM的。
来看一个影子DOM组件的例子:
<x-details role=button aria-expanded=true aria-controls=inner-details>
<div>Title</div>
#shadow-root
<div id=inner-details>Details</div>
</x-details>
注意,不要直接在html中写上这一段,
影子DOM的元素需要使用Javascript的attachShadow方法将影子DOM组件添加到一个正常的HTML节点下。
可以点击div元素:
await page.getByText('Details').click();
也可以点击x-details元素:
await page.locator('x-details', { hasText: 'Details' }).click();
过滤器
可以采用locator.filter()方法对定位出的多个元素进行筛选,filter方法接受一个对象参数,这个对象有两个可选属性:
- hasText,可以是字符串或正则表达式
- has,另一个定位器
看例子:
<ul>
<li>
<h3>Product 1</h3>
<button>Add to cart</button>
</li>
<li>
<h3>Product 2</h3>
<button>Add to cart</button>
</li>
</ul>
用文本来筛选,使用字符串时,是对大小写不敏感的:
await page
.getByRole('listitem')
.filter({ hasText: 'product 2' })
.getByRole('button', { name: 'Add to cart' })
.click();
用正则表达式,对大小写敏感:
await page
.getByRole('listitem')
.filter({ hasText: /Product 2/ })
.getByRole('button', { name: 'Add to cart' })
.click();
用另一个locator:
await page
.getByRole('listitem')
.filter({ has: page.getByRole('heading', { name: 'Product 2' })})
.getByRole('button', { name: 'Add to cart' })
.click()
严格的定位要求
在PlayWright中,如果对一个locator进行互动操作,比如click或者fill等,必须要求这个locator只定位到一个元素,否则会报错,提示有多个元素。
假设现在页面中有多个button,那么下面这个操作就会抛出一个异常:
await page.getByRole('button').click();
但是可以通过选择第几个来操作:
await page.getByRole('button').nth(1).click();
注意,
nth从0开始计数,所以此处表示选择第二个button点击
但是,如果本身就是多个元素的操作,比如计数,那就不会抛错:
await page.getByRole('button').count();
动作行为
讲讲一些PlayWright中典型的和页面元素的交互动作。注意了,前面我们介绍的locator对象,实际并不会真正在页面上去查找元素,所以,即使页面上并没有那个元素,用前面的元素定位的方法,获取一个locator对象,并不会报任何异常。只有在真正发生交互动作的时候,才会真正在页面上查找元素进行交互。这一点是和Selenium的findElement的方法是不同的,findElement会真正在页面上找元素,如果找不到就直接报异常了。
文本输入
使用fill方法可以进行文本输入,主要针对<input>, <textarea>以及有[contenteditable]属性的元素:
// Text input
await page.getByRole('textbox').fill('Peter');
Checkbox和radio
使用locator.setChecked()或者locator.checked()这两个方法都可以操作input[type=checkbox]、input[type=radio]或者有[role=checkbox]属性的元素。
await page.getByLabel('I agree to the terms above').check();
expect(await page.getByLabel('Subscribe to newsletter').isChecked()).toBeTruthy();
// f取消选中状态
await page.getByLabel('XL').setChecked(false);
select控件
使用locator.selectOption()可以操作<select>元素。
// 根据value单选
await page.getByLabel('Choose a color').selectOption('blue');
// 根据label值单选
await page.getByLabel('Choose a color').selectOption({ label: 'Blue' });
// 多选
await page.getByLabel('Choose multiple colors').selectOption(['red', 'green', 'blue']);
鼠标点击
基本操作:
// 鼠标左键单击
await page.getByRole('button').click();
// 双击
await page.getByText('Item').dblclick();
// 鼠标右键点击
await page.getByText('Item').click({ button: 'right' });
// Shift键组合鼠标点击
await page.getByText('Item').click({ modifiers: ['Shift'] });
// 鼠标悬停
await page.getByText('Item').hover();
// 点击元素的指定位置
await page.getByText('Item').click({ position: { x: 0, y: 0} });
还有当A元素覆盖在另一个B元素上面,导致B元素无法被点中,可以使用强制点击的方式:
await page.getByRole('button').click({ force: true });
还可以使用事件触发的方式实现click
await page.getByRole('button').dispatchEvent('click');
字符输入
方法locator.type()用于将一个一个字符进行输入,和fill方法不同,这是模拟了keydown, keyup, keypress这些事件,可以将这些事件触发。
await page.locator('#area').type('Hello World!');
特殊键
可以用locator.press()方法来实现键盘上一些特殊控制键的按下:
// 回车键
await page.getByText('Submit').press('Enter');
// ctrl+右箭头
await page.getByRole('textbox').press('Control+ArrowRight');
// 键盘上的$键
await page.getByRole('textbox').press('$');
可以使用的键有下面这些:
Backquote,Minus,Equal,Backslash,Backspace,Tab,Delete,Escape,ArrowDown,End,Enter,Home,Insert,PageDown,PageUp,ArrowRight,ArrowUp,F1-F12,Digit0-Digit9,KeyA-KeyZ等。
文件上传
可以使用locator.setInputFiles()方法来设置将要上传的文件,可以多个文件,注意如果使用相对路径,则表示当前的工作目录开始。
// 设置当前目录下的myfile.pdf文件作为上传文件
await page.getByLabel('Upload file').setInputFiles('myfile.pdf');
// 设置多个文件准备上传
await page.getByLabel('Upload files').setInputFiles(['file1.txt', 'file2.txt']);
// 移除上传文件列表
await page.getByLabel('Upload file').setInputFiles([]);
// 从buffer中读取文件内容作为上传文件。
await page.getByLabel('Upload file').setInputFiles({
name: 'file.txt',
mimeType: 'text/plain',
buffer: Buffer.from('this is test')
});
当完成上传文件的设置后,就可以触发或者直接点击上传按钮了。这里
locator.setInputFiles()操作的控件,必须是<input type='file'>元素。
聚焦元素
可以使用locator.focus()方法聚焦元素
await page.getByLabel('Password').focus();
拖拽
整个拖拽过程其实分为四步:
- 鼠标移动到需要拖动的元素上方
- 点住鼠标左键
- 移动鼠标到目标位置(元素)
- 松开鼠标左键
可以使用locator.dragTo()方法来实现拖拽:
await page.locator('#item-to-be-dragged').dragTo(page.locator('#item-to-drop-at'));
当然,也可以自己实现这样的拖拽过程:
await page.locator('#item-to-be-dragged').hover();
await page.mouse.down();
await page.locator('#item-to-drop-at').hover();
await page.mouse.up();
处理对话框
默认情况下,PlayWright会自动取消对话框(所有对话框都默认选择“取消”),我们这里所说的对话框包括alert, confirm, prompt。我们可以通过在触发对话框弹出之前,注册处理对话框的方式,看下面的例子:
page.on('dialog', dialog => dialog.accept());
await page.getByRole('button').click();
当设置过dialog.accept()之后,整个page后续任何弹出对话框都会按照accept处理。
但是注意了,必须在处理对话框的函数中,最后调用dialog.accept()或dialog.dismiss(),否则对话框因为没有接受到确认或取消事件,会卡住整个页面,看下面的例子,就将出现卡住的情况:
page.on('dialog', dialog => console.log(dialog.message()));
await page.getByRole('button').click(); // 会一直卡在这里
处理新的弹出页面
对PlayWright来说,页面对应的就是Page对象,当我们点击一个链接弹出一个新页面的时候,可以使用注册一个popup事件,来处理新窗口。
举个例子,假设页面上链接,文字叫“点我”,点击后会弹出新页面:
// 注册一个“弹出”的事件,注意这里是一个Promise对象
const newPagePromise = page.waitForEvent('popup');
await page.getByText('点我').click();
const newPage = await newPagePromise;
// 等待新页面的弹出.
await newPage.waitForLoadState();
console.log(await ponewPagepup.title());
如果并不清楚哪个操作会弹出新页面,那么可以事先注册on事件:
// 这里注册的函数,会在后面任何当前Page上弹出新页面时触发
page.on('popup', async popup => {
await popup.waitForLoadState();
console.log(await popup.title());
})
Frame处理
还记得Selenium中是如何处理页面中的Frame的吗?是使用switch方法来做的。PlayWright的做法和Selenium有点类似,核心都是要先定位到页面中的frame,然后再对frame中的元素进行操作。
PlayWright中有两个和Frame相关的类,一个是Frame,一个是FrameLocator。所谓的Frame,是页面中的一个<iframe>或者<frame>元素对象,可以理解为一个独立的Page对象。
而FrameLocator则是指向Frame的一个定位器。
分别来看下如何使用:
// 通过frame的name属性定位到frame对象
const frame = page.frame('frame-login');
// 通过iframe引入的url地址定位frame对象
const frame = page.frame({ url: /.*domain.*/ });
// 操作frame对象中的元素
await frame?.getByRole('button', { name: /submit/i }).click();
注意,
page.frame()方法返回的是Frame|null,所以在使用frame进行后面的操作时,需要用frame?来判断是否为null。
page.frame()方法的参数可以是一个字符串,表示frame的name属性,或者是一个对象:
{
name?: string, // 表示frame的name属性
url?: string|regexp, // 字符串或者正则表达式,表示iframe的url
}
再看看FrameLocator,其实就是混在locator中一起用:
// 定位一个在frame中的元素
const username = await page.frameLocator('.frame-class').getByLabel('User Name');
await username.fill('John');
page.frameLocator()方法的参数是一个字符串,和page.locator()方法的参数一样,通常就是css选择器或者xpath表达式。
一个Locator如果定位正好是一个ifram元素,那么也可以直接转换成FrameLocator:
const frameLocator = locator.frameLocator(':scope');
执行Javascript脚本
在PlayWright中可以使用page.evaluate()或者locator.evaluate()方法来执行脚本。执行的是一个匿名函数,或者说是一个闭包,以lambda表达式的形式体现,这个函数的返回值将传递给evaluate方法,作为这个方法的返回值。
看个简单的例子:
const href = await page.evaluate(() => document.location.href);
还可以传参数:
// 传数字参数
await page.evaluate(num => num, 42);
// 传数字数组.
await page.evaluate(array => array.length, [1, 2, 3]);
// 传对象
await page.evaluate(object => object.foo, { foo: 'bar' });
// 传elementHandle对象.
const button = await page.evaluate('window.button');
await page.evaluate(button => button.textContent, button);
// locator.evaluate()的用法
await button.evaluate((button, from) => button.textContent.substring(from), 5);
// 传多个elementHandle对象
const button1 = await page.evaluate('window.button1');
const button2 = await page.evaluate('window.button2');
await page.evaluate(
o => o.button1.textContent + o.button2.textContent,
{ button1, button2 });
// 解构多个参数的方式
await page.evaluate(
({ button1, button2 }) => button1.textContent + button2.textContent,
{ button1, button2 });
// 也可以传对象数组
await page.evaluate(
([b1, b2]) => b1.textContent + b2.textContent,
[button1, button2]);
// 混合类型的数组
await page.evaluate(
x => x.button1.textContent + x.list[0].textContent + String(x.foo),
{ button1, list: [button2], foo: null });
进阶应用
HTTP请求的拦截
可能存在这样的几种情况,一种,是后端的API接口可能还没有完全做好,或者暂时有问题,或者是第三方的,没有测试环境给我们,所以不能直接去调用,那么这时候就需要对这类接口进行Mock。
看例子:
await page.route('https://dog.ceo/api/breeds/list/all', async route => {
const json = {
message: { 'test_breed': [] }
};
await route.fulfill({ json });
});
当然,不仅仅可以mock,还可以对实际接口访问后的结果进行修改:
await page.route('https://dog.ceo/api/breeds/list/all', async route => {
const response = await route.fetch(); // 先去做请求
const json = await response.json(); // 将响应的body部分取出来
json.message['big_red_dog'] = []; // 修改响应的'big_red_dog'的值
await route.fulfill({ response, json }); // 返回
});
不仅仅是接口,还可以对请求的资源做处理,比如我们可以阻止页面上所有css资源文件的下载:
// example.spec.ts测试案例文件
import { test, expect } from '@playwright/test';
test.beforeEach(async ({ context }) => {
// 所有结尾是css的请求,都abort
await context.route(/.css$/, route => route.abort());
});
test('loads page without css', async ({ page }) => {
await page.goto('https://playwright.dev');
// ...
});
对于需要进行代理设置的,也可以采用设置proxy的方式处理:
// 在配置文件中定义全局代理
import { defineConfig } from '@playwright/test';
export default defineConfig({
use: {
proxy: {
server: 'http://myproxy.com:3128',
username: 'usr',
password: 'pwd'
}
}
});
还可以对网络请求进行监控,比如下面的例子,我们定义了对请求和响应的监控:
page.on('request', request => console.log('>>', request.method(), request.url()));
page.on('response', response => console.log('<<', response.status(), response.url()));
await page.goto('https://example.com');
还可以定义一个请求事件,主动等待请求完成后再操作:
// 匹配/api/fetch_data这个接口的请求
const responsePromise = page.waitForResponse('**/api/fetch_data');
await page.getByText('Update').click();
const response = await responsePromise;
截屏
可以将当前页面截屏保存到文件:
await page.screenshot({ path: 'screenshot.png' });
如果当前页面很长,存在滚动条,可以使用fullPage来完整截图:
await page.screenshot({ path: 'screenshot.png', fullPage: true });
还可以将截图以base64的编码方式保存到buffer中:
const buffer = await page.screenshot();
console.log(buffer.toString('base64'));
对单个元素进行截图也是可以的:
await page.locator('.header').screenshot({ path: 'screenshot.png' });
视觉对比
在PlayWright中,可以使用await expect(page).toHaveScreenshot()来对当前页面截图进行对比:
// example.spec.ts
import { test, expect } from '@playwright/test';
test('example test', async ({ page }) => {
await page.goto('https://playwright.dev');
await expect(page).toHaveScreenshot();
});
当首次运行时,会报一个错:
Error: A snapshot doesn't exist at example.spec.ts-snapshots/example-test-1-chromium-darwin.png, writing actual.,原因是在首次运行的时候还没有生成截图,所以无法进行截图对比,但是会在创建一个example.spec.ts-snapshots目录,并在其中生成截图。截图的名字类似这样:example-test-1-chromium-darwin.png,名字中的chromium-darwin代表了浏览器和操作系统。如果更换到别的系统或者浏览器,也会出现找不到截图的问题,可以使用命令行进行截图的更新:
npx playwright test --update-snapshots
截图名称也是可以更改的:
await expect(page).toHaveScreenshot('landing.png');
第二次运行测试时,就会进行截图的对比。
对比截图,可以设置各种参数,比如可以设置最大允许多少个像素点的差异,来实现一定范围内的模糊对比,这是比较好的功能:
import { defineConfig } from '@playwright/test';
export default defineConfig({
expect: {
toHaveScreenshot: { maxDiffPixels: 100 },
},
});
这是全局设置,也可以在测试案例中单独设置:
// example.spec.ts
import { test, expect } from '@playwright/test';
test('example test', async ({ page }) => {
await page.goto('https://playwright.dev');
await expect(page).toHaveScreenshot(
'landing.png',
{
maxDiffPixels: 100
},
);
});
看下还能支持哪些参数属性呢?toHaveScreenshot方法的参数如下:
- name:
String或者Array<String>类型,表示截图的名称。 - options: 可选参数,对象类型,包含以下属性:
- animations,可选参数,值为”disabled”或”allow”,默认值为”disabled”。当设置为”disabled”时,CSS的动画属性、渐变属性,以及Web自身的动画元素,都会被停止。当动画属于有限动画时,将会触发
transitionend事件,让动画快进到最后结束。如果是无限循环动画效果,则会取消无限循环属性,并快进停止到结束。这样对页面存在一些动态元素时,进行截图对比是很有利的。 - caret,可选参数,值为”hide”或”initial”,默认为”hide”,这个参数表示是否要隐藏输入框中的光标,就是那个竖线闪烁的东西,这个也会影响图像对比,所以隐藏是必须的。
- mask,可选参数,类型为
Array<Locator>,这里将可以指定定位的元素位置用一个粉色的框#FF00FF遮盖,这样可以忽略掉一些不需要对比的元素。 - maxDiffPixelRatio,数字型可选参数,值从0到1,表示最大多少比例的像素可以允许不同。
- maxDiffPixels,数字型可选参数,表示最多允许多少像素不同。
- omitBackground,布尔型可选参数,表示是忽省略背景。默认为
false。 - scale,可选参数,值为”css”或者”device”,默认为”css”,这个参数表示缩放是和css相关还是和设备相关,css相关就是正常像素大小,而和设备相关,那就会因为设备DPI的不同而不同。
- threshold,可选数字型参数,值在0到1之间,默认值为0.2,这个参数代表两张图同一个像素的颜色的差别接受程度,0表示完全一致,1表示可有所偏差,这个值的含义可以参考YIQ。
- timeout,数字型可选参数,单位是毫秒,用于指定对比的超时时间。
- animations,可选参数,值为”disabled”或”allow”,默认值为”disabled”。当设置为”disabled”时,CSS的动画属性、渐变属性,以及Web自身的动画元素,都会被停止。当动画属于有限动画时,将会触发
录制视频
PlayWright可以在测试的过程中进行录屏操作,录制完成的视频保存在测试结果目录下,默认为test-results目录,录屏在配置文件中进行配置。实际上,录屏使用的是ffmpeg这个工具。
还记得我们在初始化PlayWright的时候会自动下载浏览器吗?实际上在下载浏览器的同时,还会根据你的系统,下载对应的ffmpeg工具。
先看一个例子,这个例子定义了当测试失败后的首次重试时,会进行视频录制:
import { defineConfig } from '@playwright/test';
export default defineConfig({
use: {
video: 'on-first-retry',
},
});
video属性的值可以是一个对象,也可以是一个字符串,这个字符串必须是”off”|”on”|”retain-on-failure”|”on-first-retry”这几个值中的之一。
如果是对象,有这么几个属性:
- mode,串必须是”off”|”on”|”retain-on-failure”|”on-first-retry”这几个值中的之一
- size,可选参数,是个对象,有两个属性:
- width,数字类型,录像的视频宽度
- height,数字类型,录像的视频高度
如果这个size参数不设置,那么视频的大小会和viewPort参数设置的一致。
解释一下mode的4个值的含义:
'off'—— 不进行录制'on'—— 每个测试都会录制'retain-on-failure'—— 每个测试都会录制,但是会在最后删除所有成功的测试的录像,只保留失败的测试的录像'on-first-retry'—— 失败后首次重试时录制
PlayWright实战
接下来,我们找一个网站来进行实战,当然,不可能像一个实际的公司项目进行测试案例的编写,这里只是找一个网站,来演示一下测试的基本设计思路。
首先我们定一个测试目标,JD商城的登录功能,我们来实现自动化测试。
项目配置
我们先在PlayWright根目录下创建一个测试案例的目录,根据我们的测试对象,就取名叫tests-jd吧,需要把配置文件中的测试案例目录,指向这个地方,下面是配置文件的全部内容:
import type { PlaywrightTestConfig } from '@playwright/test';
import { devices } from '@playwright/test';
/**
* Read environment variables from file.
* https://github.com/motdotla/dotenv
*/
// require('dotenv').config();
/**
* See https://playwright.dev/docs/test-configuration.
*/
const config: PlaywrightTestConfig = {
testDir: './tests-jd',
/* Maximum time one test can run for. */
timeout: 10 * 1000,
expect: {
/**
* Maximum time expect() should wait for the condition to be met.
* For example in `await expect(locator).toHaveText();`
*/
timeout: 5000
},
/* Run tests in files in parallel */
fullyParallel: true,
/* Fail the build on CI if you accidentally left test.only in the source code. */
forbidOnly: !!process.env.CI,
/* Retry on CI only */
// retries: process.env.CI ? 2 : 0,
retries: 1,
/* Opt out of parallel tests on CI. */
workers: process.env.CI ? 1 : undefined,
/* Reporter to use. See https://playwright.dev/docs/test-reporters */
reporter: 'html',
/* Shared settings for all the projects below. See https://playwright.dev/docs/api/class-testoptions. */
use: {
/* Maximum time each action such as `click()` can take. Defaults to 0 (no limit). */
actionTimeout: 0,
/* Base URL to use in actions like `await page.goto('/')`. */
// baseURL: 'http://localhost:3000',
/* Collect trace when retrying the failed test. See https://playwright.dev/docs/trace-viewer */
trace: 'on-first-retry',
headless: false,
video: 'on-first-retry',
},
/* Configure projects for major browsers */
projects: [
{
name: 'chromium',
use: {
...devices['Desktop Chrome'],
},
},
],
};
export default config;
testDir指向了我们刚才创建的目录;retries设置了失败后的重跑次数;trace设置了重跑时会记录trace,用来调试失败案例;video设置了失败后重跑时进行录制;headless设置了不使用无头模式运行测试;
整个测试只在chromium浏览器上跑,没有设置其他浏览器。
PageObject模式
我们采用PageObject模式来进行封装,在tests-jd目录下创建一个pages目录作为所有页面类的存放位置,在其中创建两个文件,一个叫index.page.ts,一个叫login.page.ts,分别代表首页和登录页。命名方式可以做参考,只要能一眼可以看懂就可以,但是规则一定要统一。
在tests-jd下创建一个测试案例文件,叫login.spec.ts,用来写测试。整个目录结构类似下面这样:
├── tests-jd
│ ├── pages
│ │ ├── index.page.ts
│ │ ├── login.page.ts
│ ├── login.spec.ts
我们先实现index.page.ts。
import { expect, Locator, Page } from '@playwright/test';
class IndexPage {
readonly page: Page;
readonly login_link: Locator;
readonly hi_account_p: Locator;
constructor(page: Page) {
this.page = page;
this.login_link = page.getByRole('link', { name: '你好,请登录' });
this.hi_account_p = page.getByRole('paragraph', { name: 'Hi,' });
}
async to_login() {
await this.login_link.click();
await expect(this.page).toHaveTitle('京东-欢迎登录');
}
async is_logged_in() {
await expect(this.hi_account_p).toBeVisible();
}
}
export default IndexPage;
这个类中,我们定义了两个页面元素,分别是首页的登录链接,还有登录成功后的欢迎文字。看下面这张图中红框所示的部分:
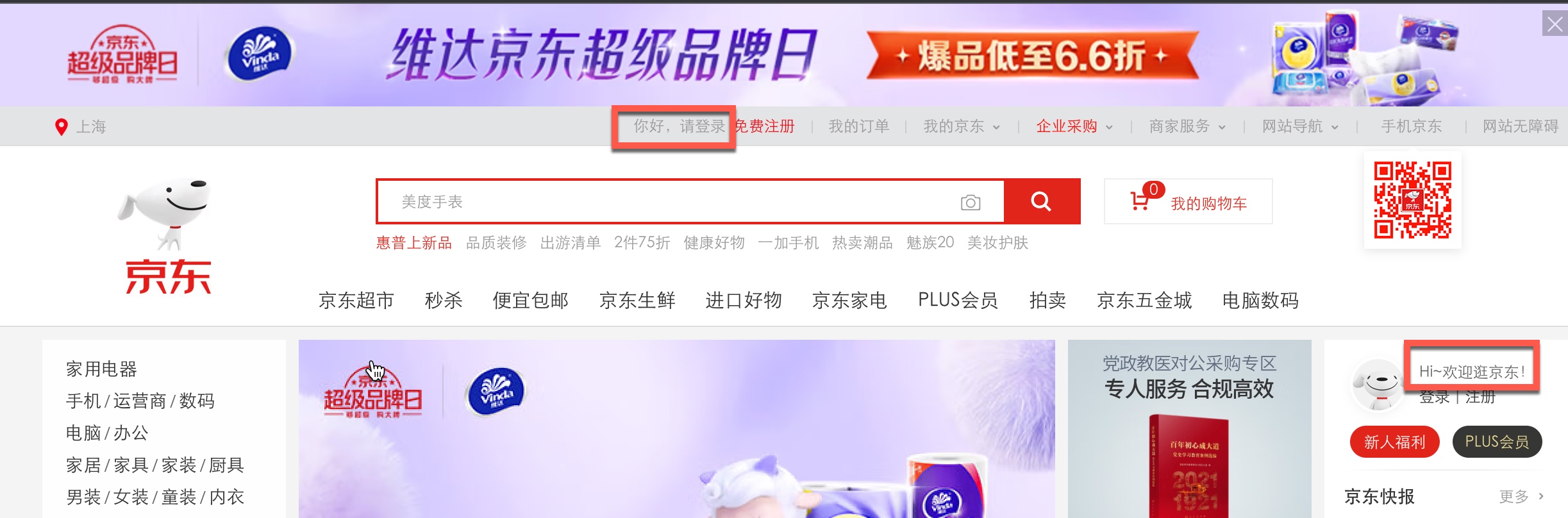
这里使用了定位稳定的getRole方法,稍作解释,getByRole('link', { name: '你好,请登录' })定位了一个link元素,也就是链接,name是可见的页面文字;而getByRole('paragraph', { name: 'Hi,' })定位了一个<p>元素,登录成功后,这里的文字应该是Hi, xxx,我们在参数中没有设置exact属性,所以会模糊匹配到这段文字。
另外,我们在index.page中定义了两个方法,分别是to_login和is_logged_in,第一个用来点击“请登录”的链接,另一个用于在登录成功后跳转回首页时进行判断是否成功登录。
再实现第二个页面,登录页面 —— login.page.ts:
import { Locator, Page } from '@playwright/test';
class LoginPage {
readonly page: Page;
readonly account_login_link: Locator;
readonly username_input: Locator;
readonly password_input: Locator;
readonly login_link: Locator;
constructor(page: Page) {
this.page = page;
this.account_login_link = page.getByRole('link', { name: '账户登录' });
this.username_input = page.getByPlaceholder('邮箱/账号名/登录手机');
this.password_input = page.getByPlaceholder('密码');
this.login_link = page.getByRole('link', { name: /登.+录/ });
}
async do_login_with_account(username: string, password: string) {
await this.page.waitForLoadState('networkidle');
await this.account_login_link.click();
await this.username_input.fill(username);
await this.password_input.type(password);
await this.login_link.click();
}
}
export default LoginPage;
这里定义了四个元素,分别是账号密码登录的tab链接account_login_link,用户名输入框username_input,登录按钮(实际是个链接)login_link。看图:
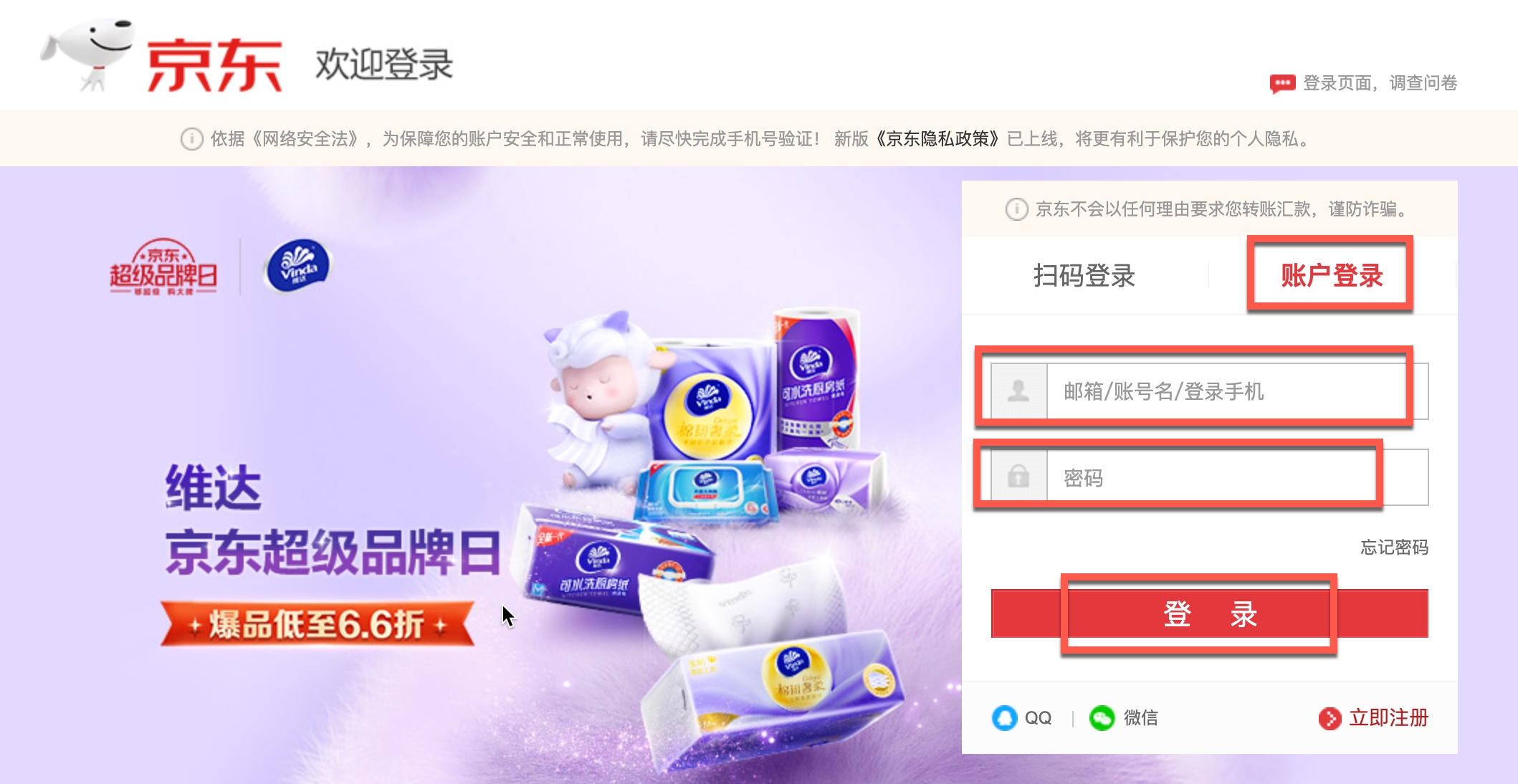
对于输入框的定位,最好的方式就是使用
getByPlaceholder,而登录这个看似按钮的链接,则用了一个正则表达式的方式,为什么呢?看看这个元素的html节点:
<a href="javascript:;" class="btn-img btn-entry" id="loginsubmit" tabindex="6" _submit="true" clstag="pageclick|keycount|login_pc_201804112|12" style="outline: rgb(109, 109, 109) none 0px;">登 录</a>
看到没,这个链接中,并不是一个单纯的登录两个字,而是加了4个代表空格的实体字符 ——
,所以我们使用正则表达式,就可以无视中间这些空格了,后面即使前端网页开发要改成三个空格的实体字符,我们也可以正常匹配到。每一个定位,都要有充分的考虑,用哪一种最合适,而不是随意的在网页上复制一个css选择器或者xpath。
另外,我们定义了一个叫do_login_with_account的方法,来处理登录,这里用了page.waitForLoadState('networkidle'),用来处理等待网络空闲时间,再进行点击,否则可能点击无响应。
案例编写
接下来,我们可以编写登录测试了,在login.spec.ts中:
import test from '@playwright/test';
import IndexPage from './pages/index.page';
import LoginPage from './pages/login.page';
test('login with account', async ({ page }) => {
await page.goto('https://www.jd.com');
const indexPage = new IndexPage(page);
await indexPage.to_login();
const loginPage = new LoginPage(page);
await loginPage.do_login_with_account('user', 'pass');
await indexPage.is_logged_in();
});
测试执行
下面跑跑看吧:
npx playwright test
这个案例实际是跑失败了,原因在于JD商城的登录需要在输入完用户名和密码后,还要做一个滑块操作,这个叫做CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),就是所谓的“人机区分验证”,避免系统被自动脚本攻击的一种手段。
在实际测试过程中,可以要求开发在测试环境部署系统时,关闭掉这个功能,以便让自动化测试可以正常运行。不要尝试去把CAPTCHA用自动化的手段操作掉,如果能操作,说明这个CAPTCHA功能并不好,没有区分人机。这不是自动化该做的事情。
案例跑失败,会跳转到测试报告的页面,PlayWright将会自己启动一个web服务,并把你引导到http://localhost:9323/这个地址查看:
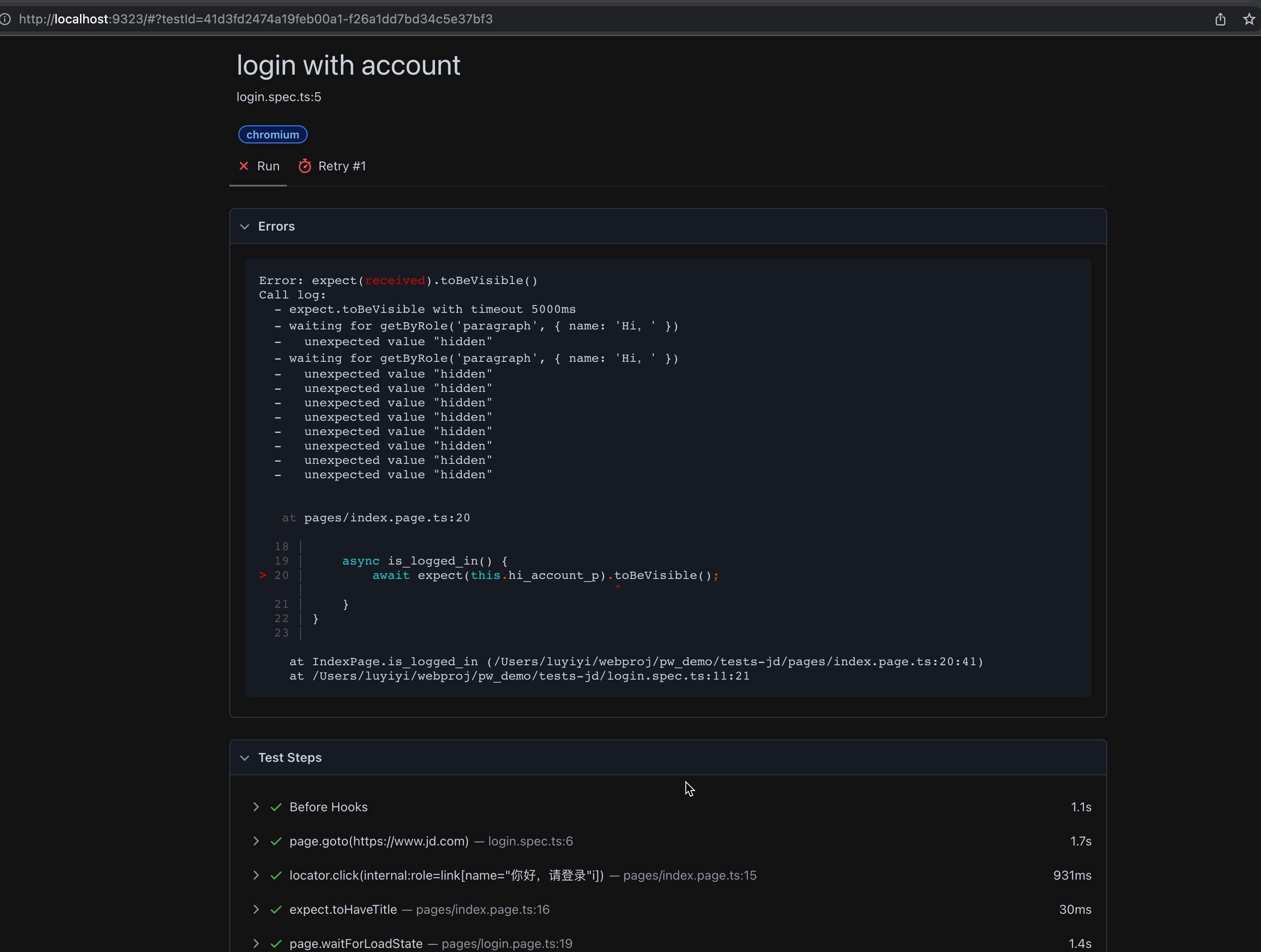
报告中显示了两次运行,第二次为失败重跑,并且可以看到每一个步骤的执行,以及时间开销。
点开Retry #1页,可以看到有trace记录和录像,这是我们配置了重跑时记录trace和录像的原因:
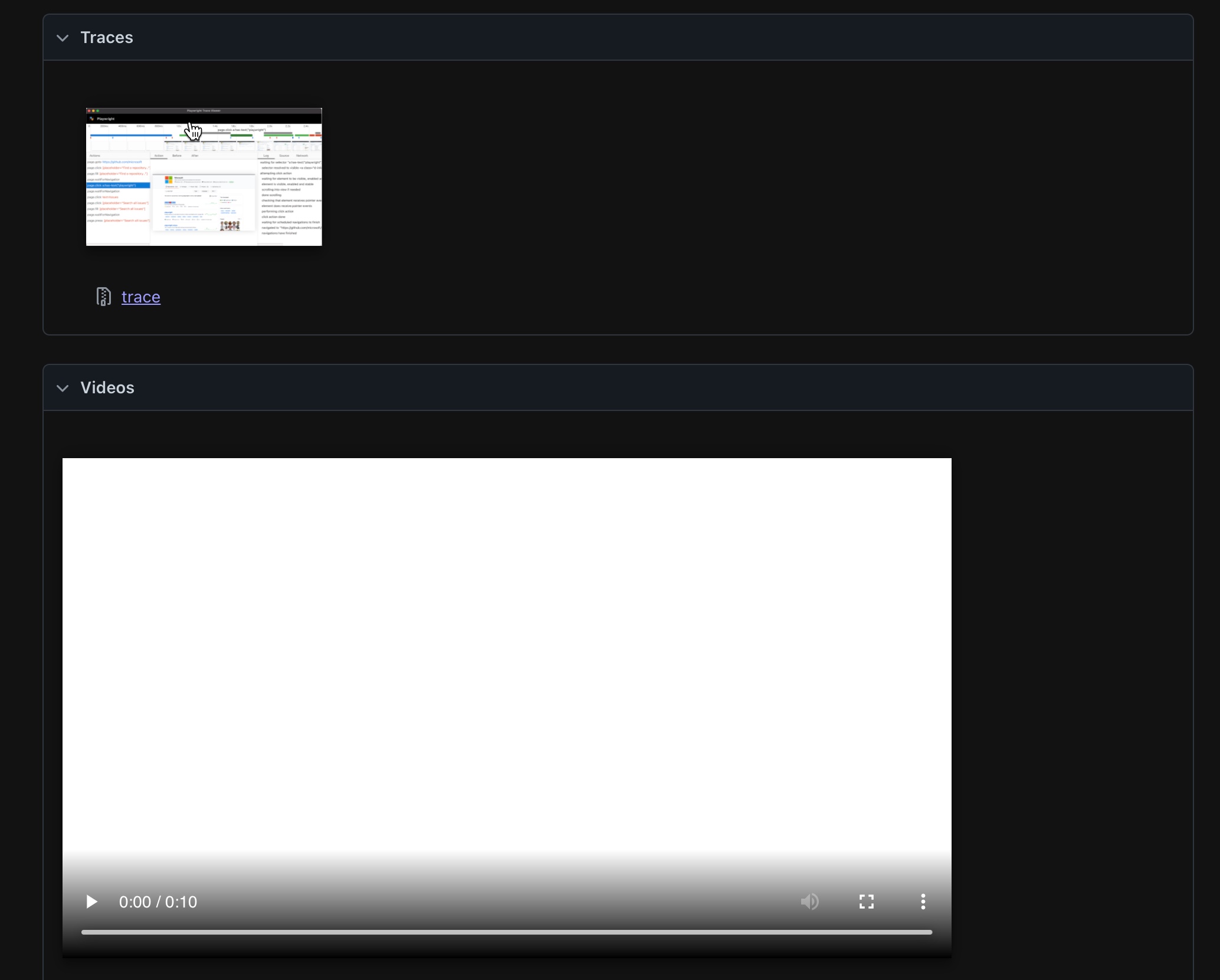
我们点开trace可以逐个步骤查看案例执行的过程,跟踪具体在哪里步出了问题,怎么出问题的。
播放video可以看到这次执行的全过程。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jimmyseraph@testops.vip
